
剑桥大学工程系团队创办的Wayve凭借机器学习算法,只需要使用摄像头和基本的卫星导航就可以实现自动驾驶汽车在陌生的道路上行驶。
自从2016年,英伟达公开了用于自动驾驶汽车的端到端深度学习技术之后,已经有不计其数的公司、单位甚至爱好者用此技术做出自动驾驶的demo。简单网络结构,可以实现摄像头输入到刹车油门方向盘输出的直接映射。然而这种低门槛也注定了它可以解决的问题并不多,很难应对具体驾驶环境上的复杂性。有专家甚至认为端到端不适合开发实用无人驾驶系统,可以做demo,大规模商用可能非常困难。
端到端只配做demo吗?由剑桥大学团队创办的Wayve无人驾驶软件公司却不这么认为。他们没有用高精地图,也没有用激光雷达等昂贵的传感器,当然也没有给汽车手工输入规则,只训练20小时数据,就可以在从未跑过的道路上驾驶。

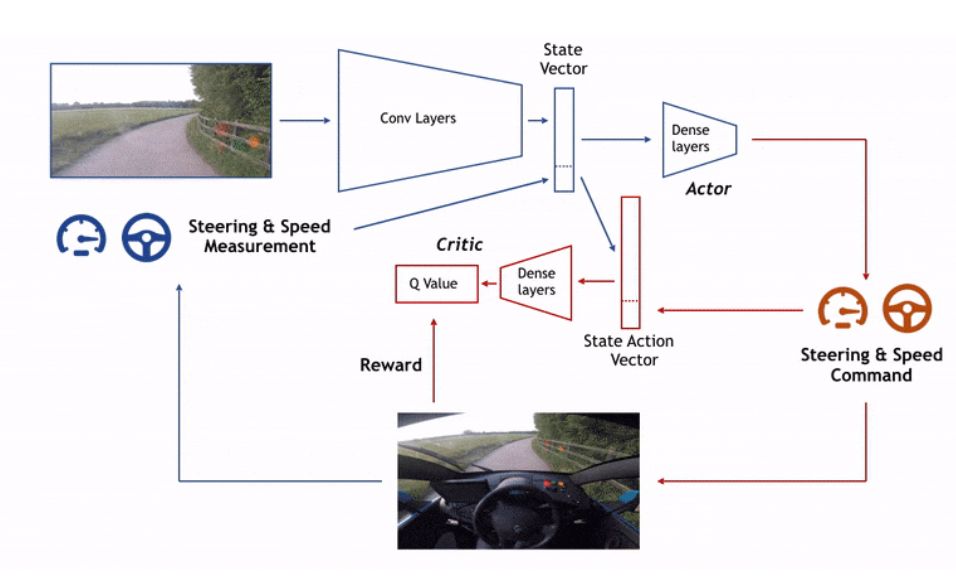
Wayve 研发团队认为既然是自动驾驶,就不需要手工编码一些规定,要充分的展现其智能的特性。团队采用了当下大热的深度学习强化学习算法,建立了一个可以像人类一样慢慢学习驾驶的自动驾驶系统。
经过探索、优化和评估三个步骤进行迭代,采用深度确定性策略梯度(Deep deterministic policy gradients,DDPG),来解决车道保持问题。

现有技术的图像分类体系结构具有数百万个参数,而Wayve团队的网络构架是一个深度网络,有4个卷积层和3个完全连接层,总共只有不到1万个参数,所有处理都在汽车GPU上执行。
在强化学习仿真测试中,通过随机生成曲线车道,以及道路纹理和车道标记,然后根据收集的数据优化策略,再不断重复。
结合了图像翻译和行为克隆的端到端零镜头框架
大多数自驾车公司使用模拟来验证他们的系统,而Wayve让自动驾驶汽车在仿真中广泛学习如何处理罕见的边缘情况。Wayve训练汽车进行模拟驾驶,并将学到的知识转化到现实世界。
Wayve没有将模拟和现实世界视为两个不同的领域,而是设计了一个框架,将两者结合起来,既可以在模拟中训练转向决策,又可以在现实世界中展现出类似的行为而无需进行真正的演示。

Wayve的模型由一对最初用于图像转换的卷积变分自动编码器式的网络组成,用于图像翻译,即无监督图像到图像的翻译网络(Unsupervised Image-to-Image Translation Networks, UNIT))。在两个域之间没有任何已知的对齐或对应关系的情况下,模型能够在它们之间进行转换。下图是一个捕捉场景主要布局的例子。值得注意的是,模拟器的视觉保真度在学习驾驶时并不是最重要的,他们的模拟世界就像卡通一样,依旧可以很好的完成仿真模拟。Wayve研究称,内容保真度比视觉保真度更重要。但是,有效地模拟其他交通参与者的行为仍然是一个巨大的挑战。

基于真实世界的驾驶数据和精心设计的边缘案例来模拟场景
汽车由基于模型的深层强化学习系统驱动,该算法从离线收集的真实数据中学习预测模型。这让模型学习并使用预测模型所想象的新场景数据来训练驾驶。

Wayve致力于开发更丰富,更强大的时态预测模型,并相信这是构建智能安全自动驾驶汽车的关键。

目前,该系统已经部署在 JaguarI-PACE 车上。这辆车赢得了2019年度欧洲年度车型的称号,未来将在整个英国和欧洲大陆收集数据。当下,让数据逐渐积累,其驱动算法可能达到人类驾驶员质量的95%,能够处理交通灯,环形交叉路口,十字路口等。
尽管有人会觉得端到端的自动驾驶系统,既不聪明也不灵活,发生问题难以解释,然而Wayve在用其强大的算法证明这种深度学习的技术不只可以做demo,未来也可以保证安全,也可以商用。